%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Reinforcement Learning

Search R1
Search-R1 is a reinforcement learning framework designed to train large language models (LLMs) capable of reasoning and calling search engines. Built upon veRL, it supports various reinforcement learning methods and different LLM architectures, enabling efficiency and scalability in tool-augmented reasoning research and development.
Model Training and Deployment
50.2K

D1
This model improves the reasoning capabilities of diffusion large language models through reinforcement learning and masked self-supervised fine-tuning with high-quality reasoning trajectories. The importance of this technology lies in its ability to optimize the model's reasoning process, reduce computational costs, while ensuring the stability of learning dynamics. Suitable for users who want to improve efficiency in writing and reasoning tasks.
Writing Assistant
48.0K
Deepcoder
DeepCoder-14B-Preview is a large language model for code reasoning based on reinforcement learning. It can handle long contexts, boasts a 60.6% pass rate, and is suitable for programming tasks and automated code generation. The model's advantage lies in its innovative training method, providing superior performance compared to other models, and being completely open-source, supporting a wide range of community applications and research.
Coding Assistant
46.6K
Chinese Picks
Hunyuan T1
HunYuan T1 is a large-scale reasoning model launched by Tencent, based on reinforcement learning technology, significantly improving reasoning capabilities through extensive post-training. It excels in long text processing and context capture, while optimizing the consumption of computing resources, thus possessing efficient reasoning capabilities. It is suitable for various reasoning tasks, and particularly excels in mathematics and logical reasoning. This product is based on deep learning and continuously optimized with actual feedback, suitable for applications in various fields such as scientific research and education.
AI Model
70.9K
Chinese Picks
Hunyuan T1
HunYuan T1 is a deep reasoning large model based on reinforcement learning, launched by Tencent. Through extensive post-training and alignment with human preferences, it significantly improves reasoning ability and efficiency. The product is based on a large-scale Hybrid-Transformer-Mamba MoE architecture, enabling the model to perform better when handling long texts. Suitable for various users who need complex reasoning and logical solutions, assisting scientific research and technological development.
AI Model
77.8K
Hunyuan T1
HunYuan T1 is an ultra-large-scale reasoning model based on reinforcement learning. Post-training significantly improves reasoning ability and aligns with human preferences. This model focuses on long-text processing and complex reasoning tasks, exhibiting significant performance advantages.
Artificial Intelligence
47.5K
Light R1 14B DS
Light-R1-14B-DS is an open-source mathematical model developed by Qihoo 360 Technology Co., Ltd. Trained using reinforcement learning based on DeepSeek-R1-Distill-Qwen-14B, it achieved high scores of 74.0 and 60.2 on the AIME24 and AIME25 mathematics competition benchmarks, respectively, surpassing many 32B parameter models. It successfully implemented reinforcement learning on an already long-chain reasoning fine-tuned model under a lightweight budget, providing the open-source community with a powerful mathematical model tool. Its open-source nature promotes the application of natural language processing in education, particularly in mathematical problem-solving, offering researchers and developers valuable research foundations and practical tools.
AI Model
69.3K

Light R1
Light-R1 is an open-source project developed by Qihoo360, aiming to train long-chain reasoning models through curriculum-style supervised fine-tuning (SFT), direct preference optimization (DPO), and reinforcement learning (RL). This project achieves long-chain reasoning capabilities from scratch through decontaminated datasets and efficient training methods. Its main advantages include open-source training data, low-cost training, and excellent performance in mathematical reasoning. The project background is based on the current training needs of long-chain reasoning models, aiming to provide a transparent and reproducible training method. The project is currently free and open-source, suitable for research institutions and developers.
Model Training and Deployment
82.5K
R1 Omni
R1-Omni is an innovative multimodal emotion recognition model that enhances model reasoning and generalization capabilities through reinforcement learning. Developed based on HumanOmni-0.5B, it focuses on emotion recognition tasks and can perform emotion analysis using visual and audio modal information. Its main advantages include strong reasoning capabilities, significantly improved emotion recognition performance, and excellent performance on out-of-distribution data. This model is suitable for scenarios requiring multimodal understanding, such as sentiment analysis and intelligent customer service, and has significant research and application value.
Emotional companionship
84.5K
Steiner 32b Preview
Steiner is a series of reasoning models developed by Yichao 'Peak' Ji, focusing on training on synthetic data through reinforcement learning, capable of exploring multiple paths and autonomously verifying or retracing during reasoning. The model aims to replicate the reasoning capabilities of OpenAI o1 and verify the scaling curve during reasoning. Steiner-preview is an ongoing project, and its open-source nature aims to share knowledge and obtain feedback from more real users. Although the model performs well in some benchmark tests, it has not yet fully achieved the reasoning scaling capabilities of OpenAI o1 and is therefore still under development.
AI Model
70.1K
Notagen
NotaGen is an innovative symbolic music generation model that enhances music generation quality through three stages: pre-training, fine-tuning, and reinforcement learning. Utilizing large language model technology, it can generate high-quality classical music scores, bringing new possibilities to music creation. The model's main advantages include efficient generation, diverse styles, and high-quality output. It is applicable in music creation, education, and research, with broad application prospects.
Music Generation
118.1K
SWE RL
SWE-RL is a reinforcement learning-based large language model reasoning technique proposed by Facebook Research, aiming to leverage open-source software evolution data to improve model performance in software engineering tasks. This technology optimizes the model's reasoning capabilities through a rule-driven reward mechanism, enabling it to better understand and generate high-quality code. The main advantages of SWE-RL lie in its innovative reinforcement learning approach and effective utilization of open-source data, opening up new possibilities in the field of software engineering. The technology is currently in the research phase and does not yet have a defined commercial pricing, but it shows significant potential in improving development efficiency and code quality.
Coding Assistant
58.8K
Mlgym
MLGym is an open-source framework and benchmark developed by Meta's GenAI team and the UCSB NLP team for training and evaluating AI research agents. By offering diverse AI research tasks, it fosters the development of reinforcement learning algorithms and helps researchers train and evaluate models in real-world research scenarios. The framework supports various tasks, including computer vision, natural language processing, and reinforcement learning, aiming to provide a standardized testing platform for AI research.
Model Training and Deployment
55.2K
VLM R1
VLM-R1 is a reinforcement learning-based visual-language model focused on visual understanding tasks, such as Referring Expression Comprehension (REC). By combining Reinforcement Learning (R1) and Supervised Fine-Tuning (SFT) methods, this model demonstrates excellent performance on both in-domain and out-of-domain data. The main advantages of VLM-R1 include its stability and generalization ability, enabling it to excel in various visual-language tasks. Built upon Qwen2.5-VL, the model leverages advanced deep learning techniques like Flash Attention 2 to enhance computational efficiency. VLM-R1 aims to provide an efficient and reliable solution for visual-language tasks, suitable for applications requiring precise visual understanding.
AI Model
62.4K
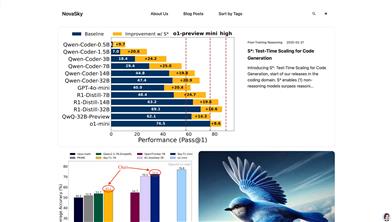
Novasky
NovaSky is an AI technology platform dedicated to enhancing the performance of code generation and inference models. It significantly improves the performance of non-inference models, making them excel in the field of code generation, through innovative test-time expansion techniques (such as S*) and reinforcement learning distillation inference. The platform is committed to providing developers with efficient and low-cost model training and optimization solutions, helping them achieve higher efficiency and accuracy in programming tasks. NovaSky's technical background originates from Sky Computing Lab @ Berkeley, with strong academic support and cutting-edge technology research foundation. Currently, NovaSky offers a variety of model optimization methods, including but not limited to inference cost optimization and model distillation techniques, to meet the needs of different developers.
Development & Tools
59.6K
Alphamaze
AlphaMaze is a decoder language model designed specifically for solving visual reasoning tasks. It demonstrates the potential of language models in visual reasoning through training on maze-solving tasks. The model is built upon the 1.5 billion parameter Qwen model and is trained with Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL). Its main advantage lies in its ability to transform visual tasks into text format for reasoning, thereby compensating for the lack of spatial understanding in traditional language models. The development background of this model is to improve AI performance in visual tasks, especially in scenarios requiring step-by-step reasoning. Currently, AlphaMaze is a research project, and its commercial pricing and market positioning have not yet been clearly defined.
AI Model
50.2K
Homietele
HOMIEtele is an innovative teleoperation solution designed for humanoid robots, leveraging reinforcement learning and low-cost exoskeleton hardware to achieve precise walking and manipulation. Its significance lies in addressing the inefficiencies and instability of traditional teleoperation systems. By utilizing human motion capture and a reinforcement learning training framework, HOMIEtele enables robots to perform complex tasks more naturally. Key advantages include efficient task completion, elimination of the need for complex motion capture equipment, and rapid training times. Primarily targeting robotics research institutions, manufacturing, and logistics industries, the price isn't publicly available, but its low-cost hardware system offers high cost-effectiveness.
Robots
55.8K
Deepscaler 1.5B Preview
DeepScaleR-1.5B-Preview is a large language model optimized by reinforcement learning, dedicated to enhancing the capabilities of solving mathematical problems. It achieves significant improvements in accuracy within long-text inference scenarios, driven by distributed reinforcement learning algorithms. Key advantages include efficient training strategies, notable performance gains, and the flexibility of open-source availability. Developed by the Sky Computing Lab and Berkeley AI Research team at the University of California, Berkeley, this model aims to advance the application of artificial intelligence in education, especially in mathematics education and competitive mathematics. Available under the MIT open-source license, it is completely free for researchers and developers to use.
Education
87.8K
R1 V
R1-V is a project focused on enhancing the generalization capabilities of visual language models (VLMs). Using verified reward reinforcement learning (RLVR) technology, it significantly improves the generalization abilities of VLMs in visual counting tasks, particularly excelling in out-of-distribution (OOD) tests. The significance of this technology lies in its ability to efficiently optimize large-scale models at an extremely low cost (training costs as low as $2.62), offering new insights into the practical applications of visual language models. The project is based on improvements to existing VLM training methods, aiming to enhance model performance in complex visual tasks through innovative training strategies. Its open-source nature also makes it a vital resource for researchers and developers exploring and applying advanced VLM technologies.
AI Model
69.6K
Fresh Picks

Tülu 3 405B
Tülu 3 405B is an open-source language model developed by the Allen Institute for AI, featuring 405 billion parameters. The model's performance is enhanced by an innovative reinforcement learning framework (RLVR), excelling particularly in mathematical and instruction-following tasks. It is optimized based on the Llama-405B model, employing techniques such as supervised fine-tuning and preference optimization. The open-source nature of Tülu 3 405B makes it a powerful tool in research and development, suitable for various applications requiring high-performance language models.
AI Model
107.9K
CUA
The Computer-Using Agent (CUA) is an advanced AI model developed by OpenAI, combining the visual capabilities of GPT-4o with advanced reasoning through reinforcement learning. It can interact with graphical user interfaces (GUIs) like a human, without relying on specific operating system APIs or web interfaces. The flexibility of CUA enables it to perform tasks in various digital environments, such as filling out forms and browsing the web. The emergence of this technology marks the next step in AI development, opening new possibilities for AI applications in everyday tools. CUA is currently in a research preview phase and is available for use by Pro users in the United States through Operator.
Personal Assistance
77.3K
Deepseek R1 Distill Qwen 1.5B
Developed by the DeepSeek team, the DeepSeek-R1-Distill-Qwen-1.5B is an open-source language model optimized through distillation based on the Qwen2.5 series. This model significantly enhances inference capabilities and performance through large-scale reinforcement learning and data distillation techniques while maintaining a compact model size. It excels in various benchmark tests, especially in mathematics, code generation, and reasoning tasks. The model supports commercial use and allows users to modify and develop derivative works, making it ideal for research institutions and enterprises looking to create high-performance natural language processing applications.
AI Model
222.2K
Deepseek R1 Distill Qwen 7B
DeepSeek-R1-Distill-Qwen-7B is a reinforcement learning-optimized reasoning model distilled from Qwen-7B. It excels in mathematical, coding, and reasoning tasks, generating high-quality reasoning chains and solutions. This model significantly enhances reasoning capabilities and efficiency through large-scale reinforcement learning and data distillation techniques, making it suitable for scenarios requiring complex reasoning and logical analysis.
Model Training and Deployment
147.7K
Deepseek R1 Distill Qwen 14B
DeepSeek-R1-Distill-Qwen-14B is a distilled model developed by the DeepSeek team based on Qwen-14B, focusing on inference and text generation tasks. This model significantly enhances inference capability and generation quality through large-scale reinforcement learning and data distillation techniques while reducing computational resource requirements. Its main advantages include high performance, low resource consumption, and broad applicability, making it suitable for scenarios requiring efficient inference and text generation.
AI Model
280.1K
Deepseek R1 Distill Qwen 32B
DeepSeek-R1-Distill-Qwen-32B, developed by the DeepSeek team, is a high-performance language model optimized through distillation based on the Qwen-2.5 series. The model has excelled in multiple benchmark tests, especially in mathematical, coding, and reasoning tasks. Its key advantages include efficient inference capabilities, robust multilingual support, and open-source features facilitating secondary development and application by researchers and developers. It is suited to any scenario requiring high-performance text generation, such as intelligent customer service, content creation, and code assistance, making it versatile for various applications.
Model Training and Deployment
120.1K
Deepseek R1 Distill Llama 70B
DeepSeek-R1-Distill-Llama-70B is a large language model developed by the DeepSeek team, based on the Llama-70B architecture and optimized through reinforcement learning. It excels in reasoning, dialogue, and multilingual tasks, supporting diverse applications such as code generation, mathematical reasoning, and natural language processing. Its primary advantages include efficient reasoning capabilities and problem-solving skills for complex tasks, while also supporting both open-source and commercial use. This model is suitable for enterprises and research institutions that require high-performance language generation and reasoning abilities.
AI Model
86.1K
Pasa
PaSa is an advanced academic paper search agent developed by ByteDance, based on large language model (LLM) technology. It can autonomously invoke search tools, read papers, and filter relevant references to obtain comprehensive and accurate results for complex academic queries. This technology is optimized through reinforcement learning, trained using the synthetic dataset AutoScholarQuery, and has shown outstanding performance on the real-world query dataset RealScholarQuery, significantly outperforming traditional search engines and GPT-based methods. The main advantages of PaSa lie in its high recall and precision rates, providing researchers with a more efficient academic search experience.
AI search
78.1K
Chinese Picks
Kimi K1.5
Kimi k1.5, developed by MoonshotAI, is a multimodal language model that significantly enhances performance in complex reasoning tasks through reinforcement learning and long-context extension techniques. The model has achieved industry-leading results on several benchmark tests, surpassing GPT-4o and Claude Sonnet 3.5 in mathematical reasoning tasks such as AIME and MATH-500. Its primary advantages include an efficient training framework, strong multimodal reasoning capabilities, and support for long contexts. Kimi k1.5 is mainly aimed at application scenarios requiring complex reasoning and logical analysis, such as programming assistance, mathematical problem-solving, and code generation.
Model Training and Deployment
257.0K
Chinese Picks
Deepseek R1 Zero
DeepSeek-R1-Zero is an inference model developed by the DeepSeek team, focusing on enhancing inference capabilities through reinforcement learning. This model exhibits powerful reasoning behaviors such as self-validation, reflection, and generating long chains of reasoning without requiring supervised fine-tuning. Its main advantages include efficient inference capabilities, immediate usability without pre-training, and outstanding performance in mathematical, coding, and reasoning tasks. The model is built on the DeepSeek-V3 architecture and is suitable for large-scale inference tasks in both research and commercial applications.
AI Model
90.8K
Chinese Picks
Deepseek R1
DeepSeek-R1, launched by the DeepSeek team, is the first generation inference model that exhibits exceptional inference capabilities through extensive reinforcement learning training, eliminating the need for supervised fine-tuning. The model excels in mathematical, coding, and reasoning tasks, comparable to the OpenAI-o1 model. Additionally, DeepSeek-R1 offers various distilled models catering to different scalability and performance requirements. Its open-source nature provides robust tools for the research community, supporting commercial use and further development.
AI Model
454.6K
- 1
- 2
- 3
Featured AI Tools
Chinese Picks

Nocode
NoCode 是一款无需编程经验的平台,允许用户通过自然语言描述创意并快速生成应用,旨在降低开发门槛,让更多人能实现他们的创意。该平台提供实时预览和一键部署功能,非常适合非技术背景的用户,帮助他们将想法转化为现实。
开发平台
143.8K
Fresh Picks

Listenhub
ListenHub 是一款轻量级的 AI 播客生成工具,支持中文和英语,基于前沿 AI 技术,能够快速生成用户感兴趣的播客内容。其主要优点包括自然对话和超真实人声效果,使得用户能够随时随地享受高品质的听觉体验。ListenHub 不仅提升了内容生成的速度,还兼容移动端,便于用户在不同场合使用。产品定位为高效的信息获取工具,适合广泛的听众需求。
音频生成
109.8K
English Picks

Lovart
Lovart 是一款革命性的 AI 设计代理,能够将创意提示转化为艺术作品,支持从故事板到品牌视觉的多种设计需求。其重要性在于打破传统设计流程,节省时间并提升创意灵感。Lovart 当前处于测试阶段,用户可加入等候名单,随时体验设计的乐趣。
AI设计工具
125.3K

Fastvlm
FastVLM 是一种高效的视觉编码模型,专为视觉语言模型设计。它通过创新的 FastViTHD 混合视觉编码器,减少了高分辨率图像的编码时间和输出的 token 数量,使得模型在速度和精度上表现出色。FastVLM 的主要定位是为开发者提供强大的视觉语言处理能力,适用于各种应用场景,尤其在需要快速响应的移动设备上表现优异。
AI模型
98.0K
English Picks

Smart PDFs
Smart PDFs 是一个在线工具,利用 AI 技术快速分析 PDF 文档,并生成简明扼要的总结。它适合需要快速获取文档要点的用户,如学生、研究人员和商务人士。该工具使用 Llama 3.3 模型,支持多种语言,是提高工作效率的理想选择,完全免费使用。
文章摘要
63.5K

Keysync
KeySync 是一个针对高分辨率视频的无泄漏唇同步框架。它解决了传统唇同步技术中的时间一致性问题,同时通过巧妙的遮罩策略处理表情泄漏和面部遮挡。KeySync 的优越性体现在其在唇重建和跨同步方面的先进成果,适用于自动配音等实际应用场景。
视频编辑
88.9K

Anyvoice
AnyVoice是一款领先的AI声音生成器,采用先进的深度学习模型,将文本转换为与人类无法区分的自然语音。其主要优点包括超真实的声音效果、多语言支持、快速生成能力以及语音定制功能。该产品适用于多种场景,如内容创作、教育、商业和娱乐制作等,旨在为用户提供高效、便捷的语音生成解决方案。目前产品提供免费试用,适合不同层次的用户。
音频生成
660.5K
Chinese Picks

Liblibai
LiblibAI是一个中国领先的AI创作平台,提供强大的AI创作能力,帮助创作者实现创意。平台提供海量免费AI创作模型,用户可以搜索使用模型进行图像、文字、音频等创作。平台还支持用户训练自己的AI模型。平台定位于广大创作者用户,致力于创造条件普惠,服务创意产业,让每个人都享有创作的乐趣。
AI模型
8.0M